简介
React 18 的核心新特性基本可以归为下面两类:
- 并发特性。为了解决大量DOM节点同时更新造成的渲染延迟问题,以及子组件IO操作被父组件阻塞的问题。React新的Fiber Reconciler通过将任务拆分成小块,支持了并发渲染。既:允许React同时渲染多版本的UI。
- 新SSR架构。允许用户将应用拆分为更小的单元,使每个单元具备独立的fetch data (server) → render to HTML (server) → load code (client) → hydrate (client)流程。
在这之外,react18还:1. 引入了新的createRoot函数用于引入新特性以实现渐进式升级;2. 自动对更新进行批处理(automatic batching)。
新特性 - Client
并发特性
在更早的时候,react提出了实验性的特性concurrent mode。通过concurrent modes实现了并发的状态更新,这里的并发有两种内含:
- 对于CPU相关的更新(如创建DOM节点,执行组件生命周期函数),这意味着高优的更新能够打断正在执行的更新。
- 对于IO相关的更新(如请求数据),这意味着在数据返回前可以在内存中提前进行渲染。
在react 18的post中,作者将其重新命名为”concurrent rendering”。意味着react18中并发不再是以一种必须选择的作用于全局的模式(all-or-nothing “mode”),而是只会在需要时被新特性触发的特性。这也和react18的渐进式升级策略相关联。
CPU-bounded updates
为了提升运行性能和用户体验,react修改渲染的调度机制,这主要包含两点:
- 将一次更新分片,允许多次更新并发执行,也支持更新的打断
- 对更新区分优先级,优先执行高优更新任务
分片
在进入分片之前我们需要先区分一下vdom树的更新(reconciliation)和渲染(render)。更新器(reconciler)是react的核心,对比两次更新前后树结构的不同;而渲染器(renderer)则将更新结果渲染到DOM上。更新器是可插拔的,我们可以用ReactDOM将其渲染为浏览器的DOM,或者用react native将其渲染为客户端的View。而核心的更新器是唯一的。
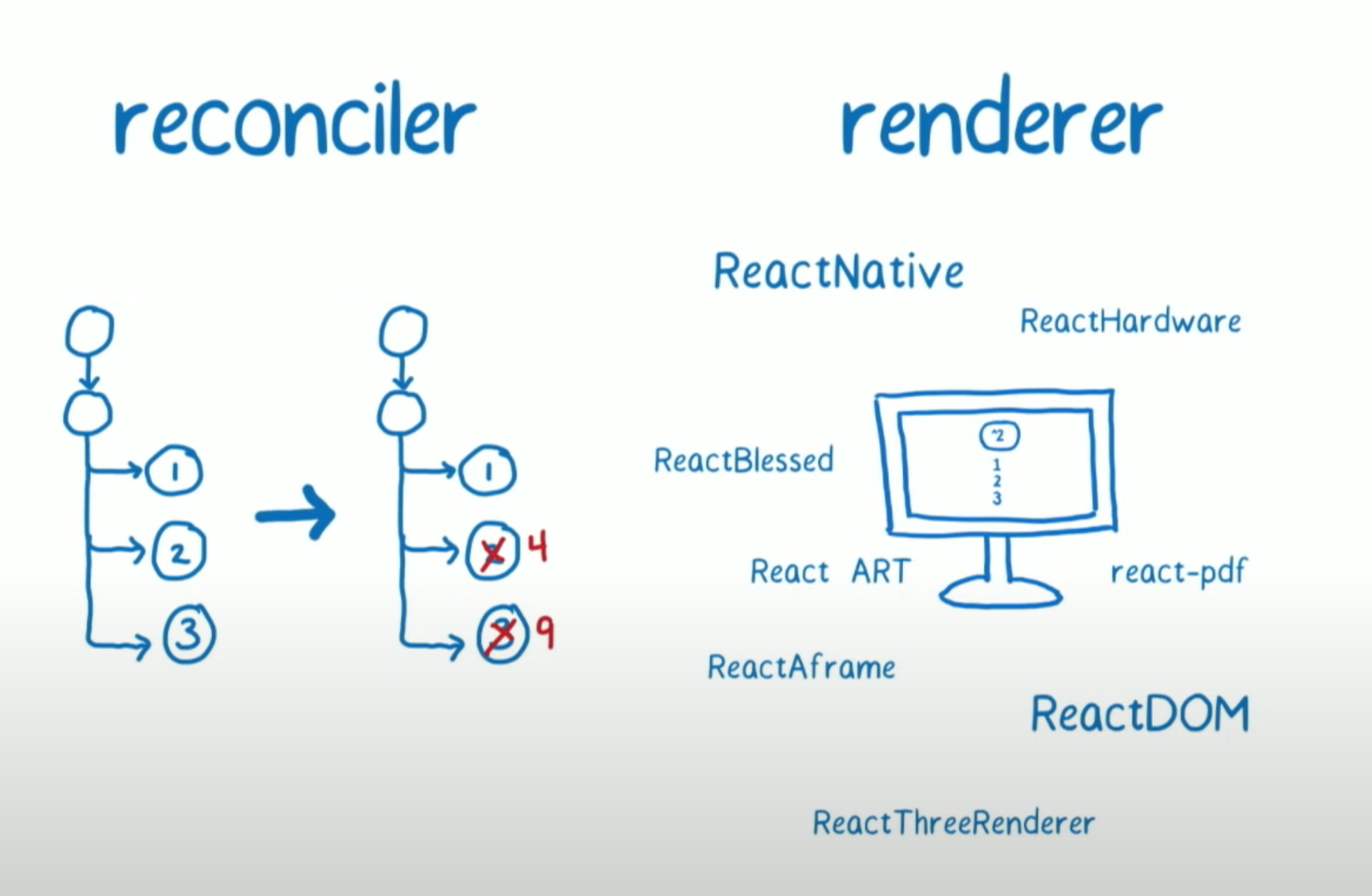
分片能力在react 16引入的Fiber Reconciler中就已实现。在此之前react使用的是Stack Reconciler,它使用递归的方式对整棵树进行更新。它的问题在于在触发一次更新后,知道这次更新任务的完成,JS线程会一直被占用而无法执行其他更加高优的任务(如:响应用户交互),造成了用户感知卡顿的问题。而Fiber Reconciler使用while loop拆解递归,将最小执行单元由一整棵树结构的更新降到了一个节点的更新;这就允许了更新被打断,为主线程提供了更多的调度能力。在新的调度能力的支持下,就可以完成高优更新优先渲染、中断过期更新等能力,更好地分配和节省计算资源。
如果你对react的实现细节感兴趣,可以阅读一下codebase overview
优先级
react18将状态更新分为两个类别(优先级):
- Urgent updates:需要快速反馈的交互,如:键盘输入、点击、触摸等
- Transition updates:UI从一个视图到另一个视图的转换
比如:在一个cms的表格场景中,当用户选中一个下拉框的选项来过滤列表的时候。用户期望在点击选项后下拉框快速收起并更新选中项(urgent updates),但是真实的过滤后的列表无需即时变化(transition updates)。
在18之前,所有的状态更新都是urgent updates,但实际上很多场景在18中可以归类为transition updates。但为了向后兼容,transition updates被作为一个可选的特性,只有当用户使用对应的API触法状态更新的时候才会被使用。
API
这个新的API就是startTransition:
1 | import { useTransition } from 'react'; |
useTransition hook 返回了:
- isPending:表示当前的状态更新还未被反映(渲染)到视图上
- startTransition:用于触发transition updates
- startTransition会被同步执行,但是这个更新会被标记,在更新被处理时react会以此判断如何渲染更新
- 渲染时,startTransition造成的更新是可以被打断的,它不会block页面。当用户的输入改变后,react将不会继续渲染过期的更新
应用场景
在以下的场景中,我们可以用startTransitionAPI来替代之前的状态更新API:
- Slow rendering:当一个更新需要消耗大量计算资源的时候
- Slow network:当一个更新需要react等待接口返回数据的时候
可以这么认为:当一个更新本身就需要耗费一些等待时间(等待可能是来源于大量计算的开销或网络的等待)时,那么用户不会在乎为这个更新再多等待一些时间,此时就可以使用startTransition API。以此,可以将计算资源更多地提供给urgent updates来提升用户体验。
react18和之前版本的性能比较可以见 这个案例
IO-bounded updates
现状
在目前,有三种渲染异步数据的方式:
- Fetch-on-render:在render函数中触发fetch(如:使用useEffect进行fetch),这经常会导致“waterfalls”(即将本可以并行的操作串联导致不必要的等待时间)。
- Fetch-then-render:等fetch完成后再进行渲染,但在fetch过程我们无法做任何事。
- Render-as-you-fetch:尽早开始fetch,同时开始渲染(在fetch返回之前),fetch返回之后重新进行渲染。
一个例子
在下面的代码中我们可以看到一个简化后的例子,描述了Render-as-you-fetch的流程:
1 | // This is not a Promise. It's a special object from our Suspense integration. |
- 首先,使用
fetchProfileData发送获取数据的请求 - 同时,react开始渲染,在渲染
ProfileDetails和ProfileTimeline时,由于read函数发现数据还没有返回,就会显示最近的祖先Suspense中fallback的内容 - 随着数据返回,react将会重新尝试render,层层解锁suspense直到完整渲染
Suspense
上面的例子介绍了Suspense的使用方法。Suspense是react为组件渲染异步获取的数据提供的一个解决方案。
In the long term, we intend Suspense to become the primary way to read asynchronous data from components — no matter where that data is coming from.
在React18之前,Suspense唯一的使用场景就是用以在懒加载React.lazy组件的时候,显示加载中的状态。而Suspense的新功能为请求库提供了一个机制:一个组件渲染所需要的数据是否已经准备好了。它帮助请求库更好地与react进行集成但并非是一个请求库,目前Facebook内部使用的是Relay,而将来我们也将会看到更多请求库支持React Suspense。同时它提供了更友好地展示数据loading状态的方式,但并未将数据获取逻辑和UI组件进行耦合。
优点
分离数据的获取和消费逻辑。在组件中对其依赖的需要消费的数据进行声明,由react自身控制渲染。而开发者可以自由控制数据获取时机(如:在用户点击,页面切换之前就开始请求)。同时请求库的提供者也可以自由控制数据获取逻辑(如:像relay这样batch请求)。
在数据消费处(组件)声明数据依赖。这允许在build阶段进行静态代码分析来进行一些处理(如:relay就以此将数据依赖编译到独立文件中,并且集成GraphQL,以在一次请求中获取这个组件所需的数据)
声明式的加载状态控制。通过Suspense API,可以更加方便地通过标签声明来控制哪些组件需要同时被加载,哪些可以分别展示不同的加载状态。当需求发生变更时也无需侵入性地改变逻辑代码。
避免race condition。在此前,想象在useEffect中触发一个fetch,在then中再setState;如果多次请求,可能会出现老的请求在更晚返回并触发setState。而使用Suspense后,数据获取逻辑本身被作为state传入(类似于promise),这个state本身的产生是同步的,避免了race condition的出现。例子。
1
2
3
4const initialResource = fetchProfileData(0);
function App() {
const [resource, setResource] = useState(initialResource);使用ErrorBoundary处理fetch错误。
Break Change
部分生命周期的执行时机和次数将会发生改变。我们可以将react的生命周期分为两类:render phase(渲染阶段)和commit phase(提交阶段),详见react-lifecycle-methods-diagram。在并发渲染时,一个组件的更新可能会被打断,也有可能会被重新恢复,这就导致了一个渲染阶段的生命周期可能会被多次执行,造成切换到并发渲染后组件发生预期外的表现。因此在将旧组件升级为并发渲染时,需要注意:
- 将render phase生命周期回调放到commit phase的回调中执行。
- 或保证render phase执行的逻辑是幂等的。即该回调中的side effect,多次执行与单次执行对系统状态的影响相同。
在开发阶段,我们可以:
- 通过React的Strict Mode来检测这些潜在的错误(Strict Mode并非直接检测副作用,而是将这些生命周期的回调执行两次以便于用户发现非幂等的副作用)
- 不再使用componentWillMount等生命周期,这些生命周期的替代方案可以参考官方文档(这也是为什么React16.9将这些函数命名为UNSAFE_componentWillMount等,并在控制台打印警告)
Automatic Batching
一个下面这个例子就完整介绍了automatic batching,直到then中的函数执行结束,react才会将更新渲染到dom上:
1 | function App() { |
优点
- 性能:减少更新次数,提升性能
- 稳定性:避免渲染半成品的状态而造成bug
历史
- react16:一次setState就会触发一次更新。
- react17:在react event handler(如onClick)中,batching会生效;但是在promises, setTimeout, native event handlers中(如上面这个异步的例子),batching不会生效。
不想batch
如果想要在setState之后立即更新,react也提供了新的APIReactDOM.flushSync来同步更新:
1 | import { flushSync } from 'react-dom'; // Note: react-dom, not react |
新特性 - Server
服务端流式渲染
new streaming server renderer
曾经的SSR
流程
在此前,react ssr可以拆分为以下几步:
server:为整个app获取数据
server:将整个app渲染为HTML并在response中返回给client
client:加载整个app的JS代码
client:将JS逻辑关联到服务端产生的静态HTML(hydration)
Hydration的解释: The process of rendering your components and attaching event handlers is known as “hydration”. It’s like watering the “dry” HTML with the “water” of interactivity and event handlers. (Or at least, that’s how I explain this term to myself.)
问题
可以看到流程中多次出现了“整个”。这就揭露了这种SSR模式的一个缺陷:在流程中,每一步都需要为整个app完成相应的计算才可以进入下一个步骤。
- You have to fetch everything before you can show anything
- You have to load everything before you can hydrate anything
- You have to hydrate everything before you can interact with anything
优化
问题的原因就在于“waterfall”: fetch data (server) → render to HTML (server) → load code (client) → hydrate (client)。这里的每个阶段都依赖于上个阶段的完成。并且每个阶段都是应用粒度的。
优化的关键就在于拆分。就如同Fiber将整个应用的更新拆分为组件粒度的更新,以实现更加复杂的调度功能;同样在SSR上也可以将应用粒度拆分为组件粒度。这样就可以避免短板效应(即加载最慢的部分拖慢了整个应用响应的时间)的出现。
新的SSR
特性
Streaming HTML(server):尽早生成HTML并传输给client。HTML不再是单次请求返回,而是流式地传输给client,每一次更新都会包含:1. 新完成渲染的HTML内容模块;2.
<script>标签,用于将HTML插入到正确的位置。API:切换
renderToString到renderToPipeableStream。Selective Hydration(client):1. 允许尽早进行hydration操作,即便剩余的HTML和JS还没有被加载。2. 允许根据用户交互来改变hydration的优先级(Selective Hydration)。
API:切换
ReactDOM.render到ReactDOM.createRoot,同时以<Suspense>来拆分整个应用SSR的粒度。
Streaming HTML
以下面这段代码为例。通过Suspense,React将不会等待评论模块(Comments)数据获取&渲染完成,在此之前就可以开始HTML的流式传输:
1 | <Layout> |
React会将其他部分和用于替代评论模块的Spinner传输给客户端
当评论模块在服务端渲染完成并传输给客户端后,客户端会用其替换Spinner
Selective Hydration
同样以上面那段代码为例,hydration同样可以被拆分,如:
可能首先hydrate其余部分
再hydrate评论模块
由于每个模块的waterfall都是互相独立的(fetch data (server) → render to HTML (server) → load code (client) → hydrate (client))。hydration也不一定会在HTML流式传输结束后才开始,即可能存在下面这种情况:
其余部分的HTML stream
其余部分的hydration
评论模块的HTML stream
评论模块的hydration
Selective Hydration
值得一提的是,由于这种粒度的拆分,除了根据数据到达顺序的hydration顺序之外,我们还可以根据用户交互来更换hydration的优先级。假设除了评论模块,我们为上面的每个模块都套上了Suspense标签(即每个模块的SSR流程都是相互独立的):
目前的加载状态,React正在hydrate边栏模块
用户对评论模块进行了点击。由于评论模块还是静态资源,目前无法响应用户交互
React判定评论模块的优先级更高,中止hydrate边栏模块,优先开始hydrate评论模块
评论模块Hydrate完成,React重新触发点击事件,此时评论模块就可以进行响应。此后,React会继续hydrate边栏模块
更多关于流式SSR的介绍可以见这个issue
Suspense
从并发渲染和新的流式SSR,我们可以看到从if(isLoading)这种命令式代码切换到<Suspense>这种声明式代码所带来的变化。通过显式地对加载状态进行声明,组件被人为分割,这个分割可能来源于:1. 代码加载的耗时;2. 依赖数据加载的耗时。通过这种声明,React可以对加载流程进行优化,将数据请求、Hydration、静态HTML生成等React管理的流程进行并行/并发,以达到优化性能的作用。
渐进式升级
React18采用了渐进式升级的策略。没有显著的对现有组件行为产生突破性变化的更新。在不使用新特性的情况下,可以在很小甚至没有代码变更下完成到React18的升级。
You can upgrade to React 18 with minimal or no changes to your application code, with a level of effort comparable to a typical major React release.
React18引入了新的ReactDOM.createRoot API,而不是使用它来替换原有的ReactDOM.render API。所有的新特性也只会在createRoot下生效,这避免了老版本代码因为新特性的引入而产生不可预期的执行结果。而对于新的并发特性(concurrent feature),官方博客同样提到,在对Facebook大量的组件进行升级的过程中,多数组件在无需代码变更的情况下就可以正常工作。
createRoot
在React18中,将会存在两个Root API:
- Legacy root API:
ReactDOM.render- 在这个API下的代码将会在legacy模式下被执行,它的执行逻辑和React17相同。这个API将被加上warning以提示它将被废弃,不推荐使用。 - New root API:
ReactDOM.createRoot- 生成一个使用react18的root,包含了react18的所有优化(包含并发特性)
root
在React中,root是顶层的数据结构,React用其获取整棵树的信息以进行渲染。
legacy:这个信息被保存在DOM中,对用户是透明的
1
2
3
4
5
6
7
8
9
10
11import * as ReactDOM from 'react-dom';
import App from 'App';
const container = document.getElementById('app');
// Initial render.
ReactDOM.render(<App tab="home" />, container);
// During an update, React would access
// the root of the DOM element.
ReactDOM.render(<App tab="profile" />, container);new:这个信息是独立的一个object,需要执行它的render方法进行渲染
1
2
3
4
5
6
7
8
9
10
11
12
13import * as ReactDOM from 'react-dom';
import App from 'App';
const container = document.getElementById('app');
// Create a root.
const root = ReactDOM.createRoot(container);
// Initial render: Render an element to the root.
root.render(<App tab="home" />);
// During an update, there's no need to pass the container again.
root.render(<App tab="profile" />);
hydration
当使用ssr时,需要使用hydrateRoot来替换createRoot。注意第二个参数还传入了JSX,因为SSR的第一次渲染比较特殊,需要将卡护短组件渲染的树和服务端渲染的树进行匹配
1 | import * as ReactDOM from 'react-dom'; |
区别
- 更新效率:在旧API中,即便container没有变化,render函数还是需要重复传入;另一方面,root无需再存储在DOM中,数据会更加安全(虽然实现上,root现在依旧会存储在DOM中)。
- 适配新SSR:移除hydrate方法,将其作为root的一个属性;由于在允许部分hydrated的情况下,render的回调不再合理,它在新API中被移除了。
其他详细内容可见issue
里程碑
- 2021-06-08 发布alpha包
- 2021-11-15 发布beta包