0:0 error Parsing error: "parserOptions.project" has been setfor @typescript-eslint/parser. The file does not match your project config: chitu-lock/https_music-ox.hz.netease.com_/xxx/index.ts. The file must be included in at least one of the projects provided
哈希链:在哈希链中,有两个关键的函数:1. H: hash function 哈希函数;2. R: reduction function 规约函数(能够将任意哈希值映射成特定字符的纯文本值,并非哈希函数的反函数)。这样,通过反复执行R和H,我们就可以得到一条哈希链(如下图所示)。由于H和R已知,对于任意输入的哈希值,通过计算结束值(即:kiebgt),我们可以判断它是否在数据库存储的某条哈希链之上;而通过开始值(即:aaaaaa)我们可以完整复原整条哈希链。
functionProfileDetails() { // Try to read user info, although it might not have loaded yet const user = resource.user.read(); return<h1>{user.name}</h1>; }
functionProfileTimeline() { // Try to read posts, although they might not have loaded yet const posts = resource.posts.read(); return ( <ul> {posts.map(post => ( <li key={post.id}>{post.text}</li> ))} </ul> ); }
functionhandleClick() { fetchSomething().then(() => { // React 18 and later DOES batch these: setCount(c => c + 1); setFlag(f => !f); // React will only re-render once at the end (that's batching!) }); }
import { flushSync } from'react-dom'; // Note: react-dom, not react
functionhandleClick() { flushSync(() => { setCounter(c => c + 1); }); // React has updated the DOM by now flushSync(() => { setFlag(f => !f); }); // React has updated the DOM by now }
新特性 - Server
服务端流式渲染
new streaming server renderer
曾经的SSR
流程
在此前,react ssr可以拆分为以下几步:
server:为整个app获取数据
server:将整个app渲染为HTML并在response中返回给client
client:加载整个app的JS代码
client:将JS逻辑关联到服务端产生的静态HTML(hydration)
Hydration的解释: The process of rendering your components and attaching event handlers is known as “hydration”. It’s like watering the “dry” HTML with the “water” of interactivity and event handlers. (Or at least, that’s how I explain this term to myself.)
由于每个模块的waterfall都是互相独立的(fetch data (server) → render to HTML (server) → load code (client) → hydrate (client))。hydration也不一定会在HTML流式传输结束后才开始,即可能存在下面这种情况:
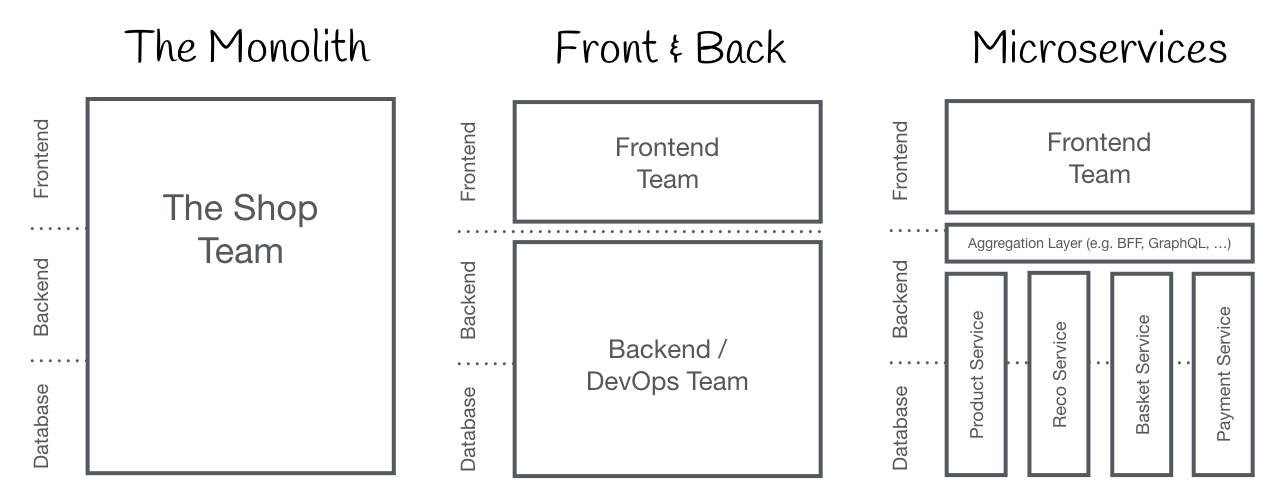
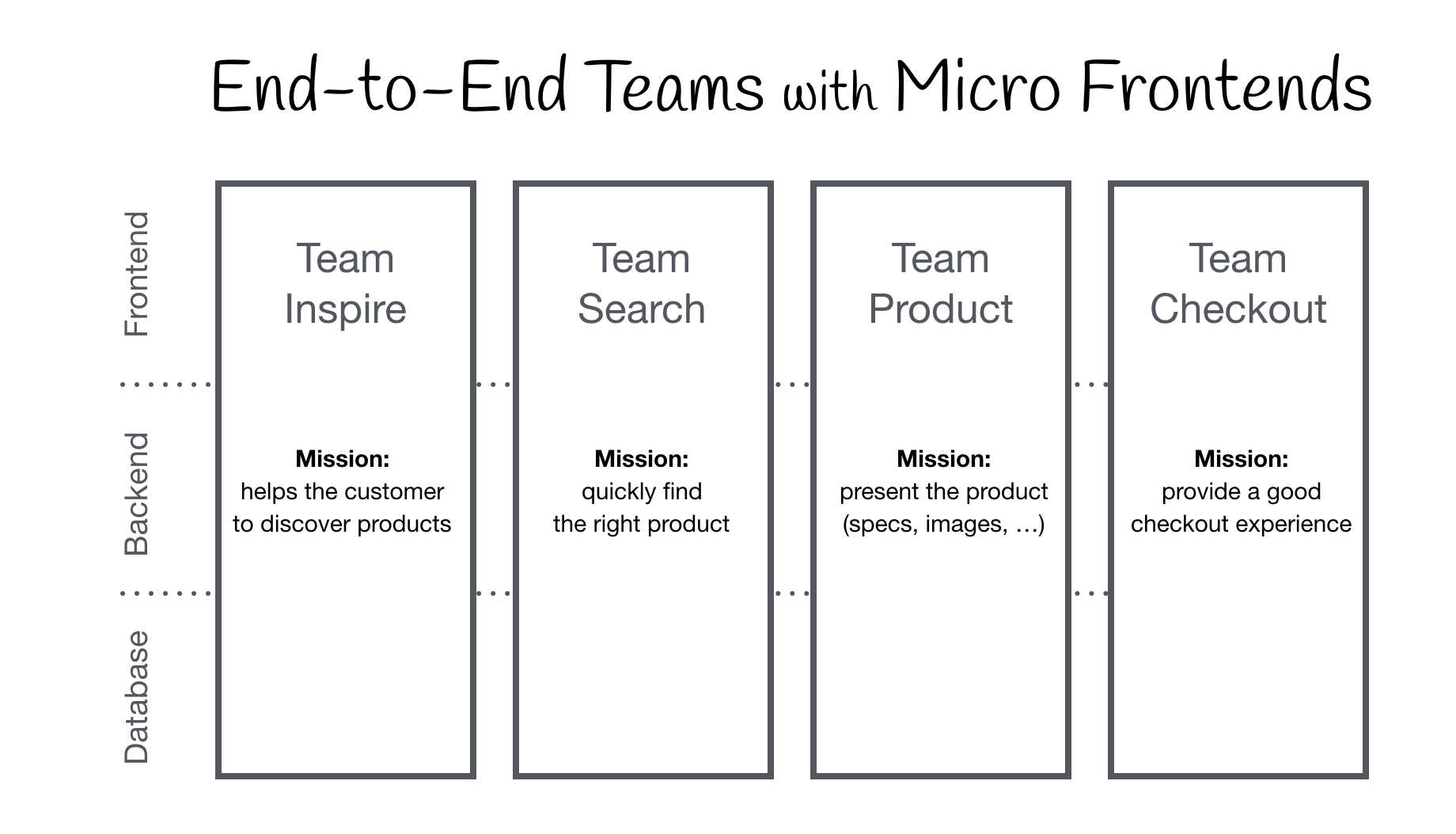
Micro Frontend is a pattern to emerge for decomposing frontend monoliths into smaller, simpler chunks that can be developed, tested and deployed independently, while still appearing to customers as a single cohesive product.
Andy Matuschak (ex Apple UI-Kit developer) expressed it once: Animation APIs parameterized by duration and curve are fundamentally opposed to continuous, fluid interactivity.
使用
例子
React-spring的使用主要分为三步:
使用动画hook配置动画并获得返回的style属性和set函数
将style属性传入animated组件
使用set函数更新动画
1 2 3 4 5 6 7
import {useSpring, animated} from'react-spring'
functionApp() { const [style, set] = useSpring(() => ({opacity: 1, from: {opacity: 0}})) // ... use set to update style return<animated.divstyle={style}>I will fade in</animated.div> }
// If the event doesn't have any button / touches left we should cancel // the gesture. This may happen if the drag release happens outside the browser // window. - if (!genericEventData.down) { + if (!is_ios_13_0_or_13_1() && !genericEventData.down) { this.onDragEnd(event) return }
To build backend API, one of the problem is validate the external data. Because the incoming data is not necessary valid. The invalid data might come from user input, wrong call of API in frontend. It might also come from malicious attackers. Thus, validation in backend is neccessary no matter frontend did it or not.
Since I’m using Typescript to build backend in Todo project, it would reduce the redundancy of code if I can make use of existing type definition in type definition. This post introduces several approaches for data validation categorized by using JSON schema or not. In my project, I tried the approach that converting Typescript types to JSON schema.
Use typescript-json-schema to pre-compile existing type to JSON schema.
Use ajv to make use of the schema from 1 to validate the request data.
Code
Typescript to JSON schema In my project, I store types used in Web API in common folder to use them both in frontend code and backend code. After write validation types in src/apiTypes, the following command in package.json is used to convert typescript to JSON schema file. (use install command name because it would be called after npm install. Please refer to lifecycle scripts)

![{\mathbf {aaaaaa}}\,{\xrightarrow[ {\;H\;}]{}}\,{\mathrm {281DAF40}}\,{\xrightarrow[ {\;R\;}]{}}\,{\mathrm {sgfnyd}}\,{\xrightarrow[ {\;H\;}]{}}\,{\mathrm {920ECF10}}\,{\xrightarrow[ {\;R\;}]{}}\,{\mathbf {kiebgt}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/bbacb4ee3811ce261fa6023c6de90718e22c7b49)